







Mùa thu năm 2020, một vài bức ảnh riêng tư chụp trong nhà của nhiều người bị phát tán trên mạng xã hội ở Venezuela. Những bức ảnh được chụp bởi camera AI từ những chiếc máy hút bụi trong nhà. Và sự thật kinh ngạc đằng sau được hé lộ.
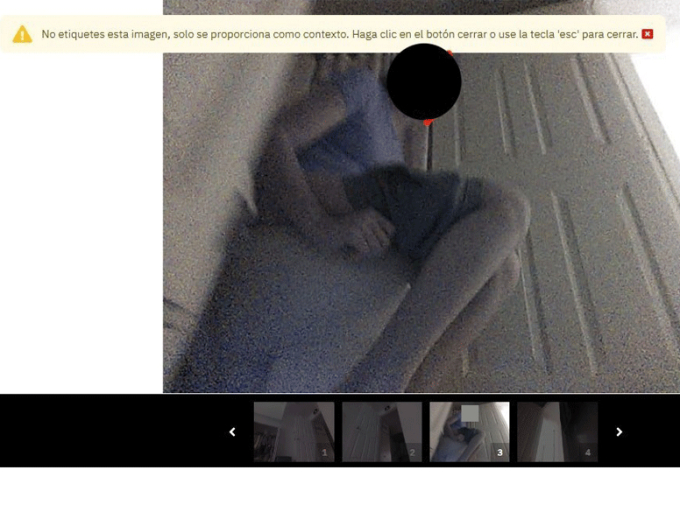 |
| Một bức ảnh chụp bởi iRobot và được che mặt bởi một hình tròn màu đen. |
Vụ rò rỉ ảnh gây sốc
Những bức ảnh này không phải được chụp bởi con người, mà bởi các phiên bản của dòng sản phẩm hút bụi Roomba J7 từ iRobot. Hình chụp được gửi tới Scale AI, một công ty khởi nghiệp ký hợp đồng với nhân viên trên khắp thế giới để phân tích dữ liệu âm thanh, hình ảnh và video cho việc phát triển trí tuệ nhân tạo.
Mặc dù đã có các biện pháp kiểm soát truy cập và lưu trữ, nhưng những bức hình này vẫn bị lộ ra, do chính các nhân viên công ty đăng tải trên các nhóm công việc. Và tới đầu năm 2022, tạp chí công nghệ MIT Technology Review đã thu được 15 ảnh chụp của những bức hình dạng này. Đó là những bức ảnh mà thường người ta sẽ không thích công khai chúng.
Trong số ảnh bị lộ, hình ảnh riêng tư nhất là của một phụ nữ trẻ trong nhà vệ sinh, với khuôn mặt được che trong tấm đầu tiên nhưng trong loạt ảnh phía sau thì không. Ở một tấm hình khác, một bé trai tầm 8-9 tuổi nhìn rõ mặt đang nằm sấp trên sàn. Đoạn tóc tam giác xõa ngang trán khi cậu nhìn chằm chằm, lộ rõ vẻ thích thú, vào vật thể đang ghi hình cậu ở ngay dưới tầm mắt.
Những bức hình khác thì chụp các căn phòng trong nhà trên khắp thế giới. Đồ nội thất, trang trí và các đồ vật để trên tường và trần nhà đều được “đóng khung” trong những chiếc hộp hình chữ nhật gắn kèm với những chú thích như “tivi”, “chậu hoa” hay “đèn trần”. Đó là những phân tích phục vụ cho nâng cấp trí tuệ nhân tạo.
iRobot – nhà cung cấp robot hút bụi lớn nhất thế giới được Amazon gần đây mua lại với giá 1,7 tỷ USD đã xác nhận những bức hình này được chụp từ dòng Roombas của họ vào năm 2020. Công ty này cho biết, tất cả bức hình đều đến từ “những robot được phát triển đặc biệt với những chỉnh sửa phần cứng lẫn phần mềm không hề có trên những sản phẩm được bán cho khách hàng”. Chúng được gửi cho những đơn vị thu thập dữ liệu nhằm phát triển AI.
Theo iRobot, các thiết bị được gắn nhãn màu xanh lá cây với nội dung “đang quay video” và những người trả tiền thu thập dữ liệu đó có quyền “xóa bất cứ thứ gì họ cho là nhạy cảm trong không gian robot hoạt động”.
 |
| Một bức hình chụp rõ mặt một cậu bé từ robot hút bụi, sau đó được che bởi tạp chí MIT Technology Review. |
Theo giải thích của iRobot, bất kỳ ai xuất hiện trên ảnh và video đều đã đồng ý để Roombas giám sát. iRobot từ chối cho MIT Technology Review xem các thỏa thuận cũng như cung cấp bất kỳ nhà thu thập dữ liệu nào để tìm hiểu thêm chi tiết thỏa thuận.
15 bức hình được chia sẻ với MIT Technology Review chỉ là lát cắt nhỏ trong một hệ sinh thái quét dữ liệu. iRobot cho biết công ty này đã chia sẻ hơn 2 triệu hình ảnh với Scale AI và một số lượng không rõ với các nền tảng chú thích dữ liệu khác. Công ty này xác nhận Scale chỉ là một trong số các nền tảng chú thích mà nó sử dụng.
Trong một email, người phát ngôn iRobot - ông James Baussmann, cho biết công ty “đã thực hiện mọi biện pháp phòng ngừa để đảm bảo dữ liệu cá nhân được xử lý an toàn và phù hợp với luật hiện hành”, và những hình ảnh được chia sẻ với MIT Technology Review “đã vi phạm văn bản thỏa thuận không tiết lộ giữa iRobot và nhà cung cấp dịch vụ“.
Vài tuần sau khi những bức ảnh được chia sẻ, Giám đốc điều hành iRobot – ông Colin Angle cho biết “iRobot đang chấm dứt mối quan hệ với nhà cung cấp dịch vụ đã làm rò rỉ hình ảnh, tích cực điều tra sự việc và thực hiện các giải pháp nhằm ngăn việc rò rỉ tương tự từ các nhà cung cấp dịch vụ khác trong tương lai”. Tuy nhiên, công ty không tiết lộ những giải pháp đó là gì.
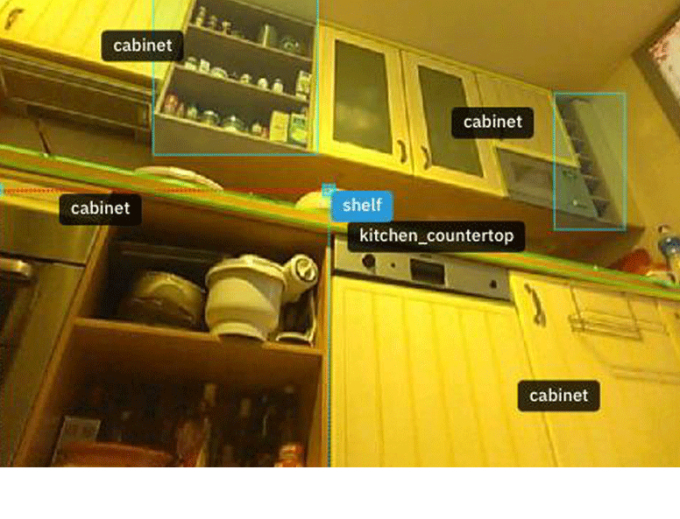 |
| Ảnh chụp từ robot hút bụi, đồ vật được đóng khung và chú thích rõ ràng. |
Không phải máy móc, có nhiều người thật đang theo dõi chúng ta
Những hình ảnh bị rò rỉ đã cho thấy toàn bộ chuỗi cung ứng dữ liệu và những điểm rò rỉ thông tin hoàn toàn mới mà ít người dùng biết đến. Theo ông Dennis Giese, nghiên cứu sinh tại Đại học Northeastern University, nghiên cứu những lỗ hổng bảo mật trên những thiết bị kết nối mạng, gồm cả robot hút bụi, cho biết những thiết bị này có “phần cứng và cảm biến mạnh mẽ. Chúng có thể đi quanh nhà mà bạn không có cách nào kiểm soát được”.
Dữ liệu này sau đó được dùng để tạo nên những robot thông minh hơn với mục đích một ngày nào đó vượt xa hơn việc hút bụi. Nhưng để những bộ dữ liệu này hữu dụng cho máy học, từng cá nhân phải xem, phân loại, gắn nhãn hay thêm ngữ cảnh vào từng bit dữ liệu. Quá trình này được gọi là chú thích dữ liệu.
“Thường sẽ luôn có một nhóm người ngồi trong một căn phòng không cửa sổ, chỉ làm việc chỉ trỏ và nhấp: “Đây là một vật thể hay không phải là vật thể”, ông Matt Beane – phó giáo sư chương trình quản lý công nghệ tại Đại học California, thành phố Santa Barbara (Mỹ), nghiên cứu về việc của con người đằng sau robot, giải thích.
Bà Jessica Vitak – nhà khoa học thông tin và giáo sư khoa truyền thông của Đại học Maryland và Cao đẳng nghiên cứu thông tin, cho biết: “Chúng tôi đối xử với máy móc khác với con người. Đối với tôi, việc chấp nhận một chiếc máy hút bụi nhỏ xinh di chuyển khắp phòng mình dễ dàng hơn nhiều so với việc ai đó đi khắp nhà mình với chiếc máy quay”.
Vậy nhưng đó thực chất là điều đang diễn ra. Không chỉ là một robot hút bụi đang theo dõi bạn trong nhà vệ sinh mà một con người có thể cũng đang nhìn.
Việc cần dữ liệu thô cho những thuật toán máy học kéo theo nhu cầu nhân công rất lớn, và đó là lúc cần đến quá trình chú thích dữ liệu. Là một ngành công nghiệp trẻ đang phát triển, chú thích dữ liệu được dự đoán sẽ đạt 13,3 tỷ đô giá trị thị trường vào năm 2030.
Sự phát triển của lĩnh vực này phần lớn để đáp ứng nhu cầu dán nhãn cho dữ liệu để đào tạo các thuật toán. Ngày nay, những người dán nhãn thường là nhân viên hợp đồng được trả lương thấp ở các nước đang phát triển.
Đứng đằng sau những gì chúng ta xem là “tự động” trực tuyến, những nhân viên này giúp loại bỏ những cái xấu trên mạng ra khỏi mạng xã hội bằng cách phân loại và gắn cờ đánh dấu những bài đăng một cách thủ công, cải thiện phần mềm nhận diện giọng nói bằng cách ghi lại âm thanh chất lượng thấp, cũng như giúp robot hút bụi nhận diện đối tượng xung quanh bằng cách gắn thẻ ảnh và video.
Scale AI là công ty dẫn đầu thị trường trong lĩnh vực này. Thành lập năm 2016, công ty đã xây dựng một mô hình kinh doanh qua việc ký hợp đồng với những nhân công làm việc từ xa tại các quốc gia kém giàu có với những dự án và nhiệm vụ giá rẻ trên Remotasks – nền tảng độc quyền trong việc tìm nguồn cung ứng nhân lực từ đám đông (hay còn gọi là crowdsourcing).
Năm 2020, Scale công bố một dự án mới có tên Dự án IO. Dự án phân tích những bức ảnh được chụp một góc 45 độ từ dưới sàn, chụp tường, trần và sàn của các căn nhà trên khắp thế giới, cũng như những sự việc xảy ra bên trong – gồm cả người với những khuôn mặt hiện rõ với những nhãn dán. Những bức ảnh giống 15 bức ảnh rò rỉ từ máy hút bụi Roombas. Những nhân viên dán nhãn cho các bức ảnh bàn luận về những bức ảnh trong dự án IO trên Facebook, Discord và các nhóm khác để chia sẻ kinh nghiệm.
Nói về tình trạng chia sẻ nội dung này, Kevin Guo – giám đốc điều hành của Hive, một công ty đối thủ của Scale cho biết: “Những nhân công này phân tán khắp nơi. Theo quy định là không được, nhưng rất khó để kiểm soát”.
“Điều khá ngạc nhiên đối với tôi là những hình ảnh ấy được chia sẻ trên một nền tảng chia sẻ mở (crowdsourcing)”, bà Olga Russakovsky – điều tra viên tại phòng thí nghiệm Visual AI của Đại học Princeton cho biết. Việc phụ thuộc vào các chương trình chú thích dữ liệu ở nơi khác không phải là cách an toàn để bảo mật dữ liệu.
“Khi bạn có dữ liệu nhận được từ khách hàng, dữ liệu đó thường sẽ nằm trong cơ sở dữ liệu được bảo mật”, ông Pete Warden – nhà nghiên cứu lĩnh vực thị giác máy tính và là nghiên cứu sinh tại Đại học Stanford cho biết. Thế nhưng với việc đào tạo lĩnh vực học máy, tất cả dữ liệu khách hàng được tổng hợp thành một lô lớn, mở rộng “vòng tròn” những người có thể truy cập.
 |
| Ảnh: Technology Review. |
Về phần mình, iRobot cho biết công ty chỉ chia sẻ một tập con hình ảnh với những đối tác chú thích dữ liệu, gắn cờ vào bất kỳ hình ảnh có thông tin nhạy cảm và thông báo cho giám đốc bảo mật nếu những thông tin này được phát hiện. Công ty này nêu rõ “Khi phát hiện một hình ảnh mà người dùng đang trong tư thế nhạy cảm, như khỏa thân hay tương tác tình dục, nó lập tức sẽ bị xóa bỏ cùng với toàn bộ các bức hình khác trong nhật trình đó”.
Dù vậy, công ty không nêu rõ việc gắn cờ này sẽ được làm tự động bởi thuật toán hay bởi con người. Bởi những hình ảnh bị rò rỉ cho thấy vẫn bị lọt nhiều hình ảnh nhạy cảm ra ngoài. Ngoài ra ông Baussmann cho biết iRobot sẽ “loại bỏ tất cả thông tin nhận dạng ra khỏi bức hình… nên nếu chúng rơi vào tay kẻ xấu thì sẽ không thể truy ngược lại để nhận diện được họ”.
Nhưng theo chính sách iRobot, khuôn mặt không được xem là nhạy cảm, dù cho đó là vị thành niên. “Để dạy robot tránh con người và hình ảnh người” – một chức năng được quảng bá tới những khách hàng lo lắng về vấn đề riêng tư, công ty cho biết “trước hết cần dạy robot biết con người là gì. Và để làm như vậy, việc thu thập dữ liệu về con người là cần thiết cho việc đào tạo”, cho biết hình ảnh khuôn mặt là một phần trong dữ liệu đó. Thế nhưng theo William Beksi, giáo sư ngành khoa học máy tính điều hành phòng thí nghiệm thị giác robot tại Đại học Texas, hình ảnh khuôn mặt có thể không thực sự cần thiết cho các thuật toán nhận diện con người.
“Nếu là một công ty lớn, bạn sẽ lo ngại về vấn đề riêng tư và sẽ xử lý trước những hình ảnh này”, ông nói. Chẳng hạn, bạn có thể làm các khuôn mặt mờ đi trước khi chúng rời khỏi thiết bị và “trước khi gửi những bức hình tới bên chú thích dữ liệu”. “Điều đó khá là cẩu thả, đặc biệt có cả trẻ thành niên được ghi lại trong video”, ông nói.
Theo ông Warden, việc chụp lại mặt vốn đã vi phạm quyền riêng tư. “Vấn đề ở chỗ khuôn mặt bạn như một mật khẩu không thể thay đổi. Một khi ai đó ghi lại “chữ ký” trên khuôn mặt bạn, họ có thể dùng nó vĩnh viễn để tìm bạn trong mọi bức hình và video”.
Hơn nữa, “các nhà lập pháp và thực thi quyền riêng tư coi sinh trắc học, gồm khuôn mặt, là những thông tin nhạy cảm”, bà Jessica Rich – luật sư lĩnh vực quyền riêng tư và từng làm giám đốc Cục bảo vệ người tiêu dùng của FTC cho biết. Đặc biệt khi hình trẻ vị thành niên xuất hiện trên camera. Bà cho biết: “Việc có sự chấp thuận của nhân viên không đồng nghĩa có sự đồng ý từ trẻ em. Nhân viên không có quyền cho phép thu thập dữ liệu về các cá nhân khác, chứ chưa nói đến việc có trẻ em liên quan”, bà nói.
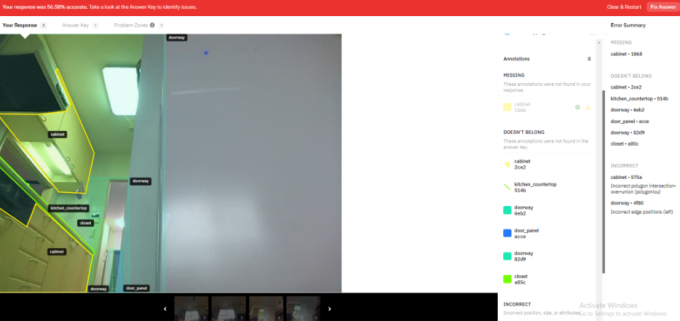 |
| Bức ảnh đang được chú thích dữ liệu (Ảnh: Technology Review) |
Điều bất ngờ đằng sau những điều khoản bạn từng đồng ý
Trên thực tế, iRobot cho biết công ty đã triển khai nhiều biện pháp bảo vệ quyền riêng tư và bảo mật trong các thiết bị của khách hàng, bao gồm việc sử dụng mã hóa, thường xuyên vá các lỗ hổng bảo mật, hạn chế và giám sát quyền truy cập thông tin của nhân viên nội bộ, cũng như cung cấp cho khách hàng thông tin chi tiết về dữ liệu thu được.
Thế nhưng có một khoảng cách lớn giữa cách công ty nói về quyền riêng tư với cách mà người dùng hiểu về nó.
Những định nghĩa mở rộng về thu thập dữ liệu thường được chấp nhận theo chính sách quyền riêng tư được diễn đạt mơ hồ của các công ty, hầu như đều chứa một số ngôn từ cho phép sử dụng dữ liệu cho mục đích “cải thiện sản phẩm và dịch vụ” – mà theo bà Rich là “về cơ bản cho phép làm bất cứ gì”.
Quả thực, trong 12 chính sách về quyền riêng tư của robot hút bụi mà MIT Technology Review từng xem qua đều có nội dung tương tự như “cải thiện sản phẩm và dịch vụ”. Hầu hết các công ty mà MIT Technology Review liên hệ đều không trả lời câu hỏi liệu việc “cải tiến dịch vụ” có bao gồm các thuật toán máy học hay không, ngoại trừ Roborock và iRobot xác nhận là có.
Hầu hết chính sách về quyền riêng tư của các công ty thậm chí không đề cập đến việc thu thập các dữ liệu nghe nhìn, trừ vài trường hợp ngoại lệ. Như chính sách của iRobot ghi rõ sẽ thu thập loại dữ liệu này chỉ khi một cá nhân chia sẻ những hình ảnh qua ứng dụng di động. Chính sách của LG cho thiết bị Hom-Bot Turbo+ có máy quay và AI cho biết ứng dụng thu thập dữ liệu nghe nhìn, gồm “dữ liệu âm thanh, điện tử, hình ảnh hay các thông tin tương tự như ảnh hồ sơ, bản ghi âm giọng nói và bản ghi video”.
Chính sách của Samsung cho máy hút bụi Jet Bot AI+ cảm biến lidar và Powerbot R7070 là sẽ thu thập “thông tin lưu trữ trên máy, như hình ảnh, danh bạ, nhật trình, tương tác chạm, thông tin cài đặt và lịch” và “bản ghi âm giọng nói khi bạn dùng khẩu lệnh để điều khiển hay liên hệ với bên dịch vụ khách hàng”. Trong khi đó, chính sách của Roborock không đề cập đến dữ liệu nghe nhìn, mặc dù đại diện công ty cho biết người dùng ở Trung Quốc có lựa chọn chia sẻ hay không.
 |
| Ảnh: Technology Review. |
Bà Helen Greiner, đồng sáng lập iRobot và hiện điều hành một công ty khởi nghiệp có tên Tertill chuyên bán robot làm vườn, nhấn mạnh rằng khi thu thập những dữ liệu này, các công ty không cố vi phạm quyền riêng tư của khách hàng, mà chỉ cố gắng tạo ra sản phẩm tốt hơn – hay trong trường hợp của iRobot, là “làm sạch tốt hơn”.
Người tiêu dùng thường đồng ý để dữ liệu của mình được theo dõi ở các mức độ khác nhau trên các thiết bị điện tử hay dùng. Đây là một thực tế chỉ trở nên phổ biến hơn trong thập kỷ qua, khi trí tuệ nhân tạo “đói dữ liệu” ngày càng được tích hợp vào hàng loạt các sản phẩm và dịch vụ mới. Phần lớn công nghệ này dựa trên machine learning (hay học máy), một kỹ thuật sử dụng kho dữ liệu lớn – gồm giọng nói, khuôn mặt, nhà cửa và các thông tin cá nhân khác để đào tạo các thuật toán nhằm nhận diện các kiểu mẫu.
Những thông tin thực tế là những dữ liệu hữu ích nhất, và việc thu thập chúng từ môi trường thực, như trong nhà đặc biệt giá trị. Thông thường, chúng ta chấp nhận đơn giản bằng cách dùng sản phẩm, khi các chính sách riêng tư được ghi chú mơ hồ cho phép công ty toàn quyền trong việc phổ biến và phân tích thông tin người dùng.
 |
| Ảnh: Technology Review. |
Sự khao khát dữ liệu sẽ chỉ tăng lên trong những năm tới. Những chiếc máy hút bụi chỉ là một tập con nhỏ trong số các thiết bị kết nối đang dần phổ biến trong cuộc sống chúng ta. Và những tên tuổi lớn trong lĩnh vực robot hút bụi như iRobot, Samsung, Roborock và Dyson đang lên tiếng về những tham vọng lớn hơn nhiều so với việc lau nhà tự động. Người máy, bao gồm người máy gia đình từ lâu đã là giải thưởng thực sự. Việc các công ty sản xuất robot hút bụi đã đầu tư vào các tính năng và thiết bị khác sẽ đưa chúng ta gần hơn tới một tương lai có robot hỗ trợ.
Dù vậy, không nỗ lực nào xử lý được những vấn đề trước sự lớn mạnh của thị trường chú thích dữ liệu và mức độ gia tăng nhanh chóng của những công ty thu thập dữ liệu cùng những nhân viên dãn nhãn hợp đồng.








Trí tuệ nhân tạo sẽ loại bỏ vai trò của bác sĩ
Trí tuệ nhân tạo sẽ loại bỏ vai trò của bác sĩ
ChatGPT: Khi trí tuệ nhân tạo 'phổ cập' mọi nhà
ChatGPT: Khi trí tuệ nhân tạo 'phổ cập' mọi nhà
Elon Musk cảnh báo trí tuệ nhân tạo là 'một trong những rủi ro lớn nhất' đối với nền văn minh
Triển vọng tương lai cho trí tuệ nhân tạo trên thị trường việc làm là gì?
Cùng chuyên mục
Thúc đẩy tiêu dùng xanh từ những thay đổi trong nhận thức người dân
Phó Thủ tướng: Nhà khoa học làm đúng, thất bại sẽ được miễn trừ trách nhiệm
Hội Nữ trí thức Hải Phòng ghi nhận nhiều kết quả nghiên cứu khoa học trong 6 tháng đầu năm
Sun Group ra mắt Sun Signature: Kiến tạo hệ sinh thái đặc quyền chưa từng có trên một nền tảng duy nhất
Hà Nội đẩy mạnh truyền thông về khoa học, công nghệ và chuyển đổi số giai đoạn 2026-2027
Những nữ nhà báo bền bỉ nối những nhịp cầu yêu thương